Architecture and components¶
The following is the architecture layout for Percona Server for MySQL based deployment variant of Percona Distribution for MySQL with Group Replication.
Architecture layout¶
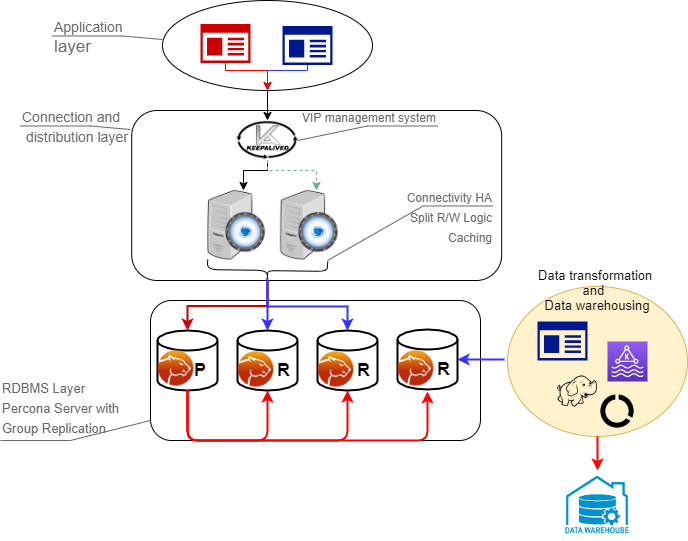
Components¶
The architecture is composed of two main layers:
Connection and distribution layer¶
The connection and distribution layer consists of the following:
-
Application to proxy redirection mechanism. This mechanism can be anything from a Virtual IP managed by Keepalived local service to a DNS resolution service like Amazon Route 53. The mechanism’s function is to redirect the traffic to the active Proxy node.
-
Proxy connection distribution. The distribution consists of two or more nodes and its role is to redirect the traffic to the active nodes of the Group Replication cluster. In cases like ProxySQL where the proxy is a level 7 proxy and can perform a read / write split, this layer is also in charge of redirecting writes to the Primary node and reads to the replicas, and of high availability to prevent a single point of failure.
RDBMS layer¶
The data layer consists of the following:
-
Primary (or source) node serving write requests. This is the node that accepts writes and DDL modifications. Data will be processed following the ACID (atomicity, consistency, isolation, durability) model and replicated to all other nodes.
-
Replica nodes serving read requests. Some replica nodes can be elected Primary in case of the Primary node’s failure. A replica node should be able to leave and join back to a healthy cluster without impacting the service.
-
Replication mechanism distributing changes across nodes. In this solution, it is done with Group Replication. Group Replication is a tightly coupled solution, which means that the database cluster is based on a Datacentric approach (single state of the data, distributed commit). In this case, the data is consistent in time across nodes though this type of replication requires a high performant link. Given that, the main Group Replication mechanism does not implicitly support Disaster Recovery (DR) and geographic distribution is not permitted.
The node characteristics such as CPU/RAM/Storage are not relevant to the solution design. They must reflect the estimated workload that the solution will have to cover, and this is a case by case identification.
However, it is important that all nodes that are part of the cluster must have the same characteristics. Otherwise, the cluster is imbalanced and services will be affected.
As a generic indication we recommend using nodes with at least 8 cores and 16GB RAM when in production.